A few days ago Nanopore sent me a technical challenge as part of their interview process. I’ve set up a a GitHub repo to track development progress. These are some notes before I go headlong into coding:
Day 1 – tech challenge received
The challenge involves building a DAG for a workflow. The first thing I did on receiving it was sketch out their example DAG to get a better feel for the behaviour of each node:
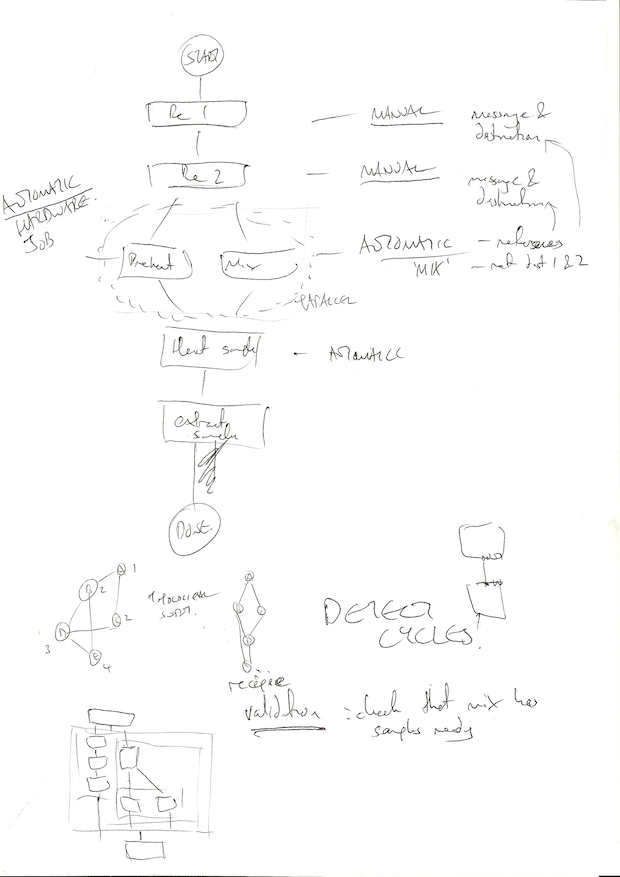
Forgive the quality of these scans, I’m cobbling this together fast! The first sketch highlighted the scope of the design for the DAG:
- Whether a task is manual or automatic.
- Functional behaviour (e.g. display message, move sample).
- Specification of ‘ports’ on device
- Input where user adds sample. I’ll call these input_a, input_b etc.
- Output where user removes sample. I’ll call these output_a, output_b etc.
- General input/output ‘cells’ which is where the device is moving samples around, which I’m assuming to be a 2×2 grid from seeing the VolTRAX videos. I’ll call these cell_1_1, cell_2_4 etc.
- Certain cells do work, e.g. heating, applying magnetic field. I’ll treat these like regular cells but give them special IDs like heater_1.
Example tasks and data required:
- Add ingredient (manual): show message; input port ID; destination cell to move sample to.
- Mix ingredients (auto): two registers to mix; cell where the sample ends up.
- Preheat (auto): heater temperature; heater ID if there is more than one.
- Heat sample (auto): input cell location; time on heater; header ID if there is more than one; output cell location.
- Extract sample (manual): show message; output port ID.
This highlights some missing data in the DAG, that the operations of moving between certain cells should perhaps be nodes in themselves. For example the ‘heat sample’ task would be simpler if it was split up using move tasks:
- Move sample from cell_1_2 to heater_1.
- Stay on (preheated) heater_1 for 2 seconds.
- Move sample from heater_1 to cell_2_3.
A few other things came up in this sketch:
- Being a DAG it needs to avoid cycles.
- The ports/cells give me a conceptual device to work with.
- Validation. If I know all the inputs and outputs then I can run a validation step to ensure that anything that uses a particular cell or input has had that cell or input set up; i.e. check hardware dependencies.
- To run the program the nodes will need to be sorted topologically. Not necessary if nodes are inserted in-order.
- My sketch at the bottom left is my thinking about organising parallel data tasks which let to builder concepts detailed in next post. I think I can get a nice DSL together.
