Last night I got into a insomniac code-spiral about replicating some of Rust’s borrowing warnings in C++. In place of Rust’s initial variable declararion of let I use wrapper Owner<T> in C++ that internally tracks ownership. Passing to another Owner<T> will take the ownership, or a Borrower<T> class can accept a properly owned value and reference it as a constant.
// Function borrowing a value can only read const ref
static void use(Borrower<int> v) {
(void)*v;
}
// Function can mutate value via ownership which generates 'warnings' if used again incorrectly
static void use_mut(Owner<int> v) {
*v = 5;
}
int main() {
// Rather than just 'int', Owner<int> tracks the lifetime of the value
Owner<int> x{3};
// Borrowing value before mutating causes no problems
use(x);
// Mutating value passes ownership, has_been_moved set on original x
use_mut(std::move(x));
// Uncomment for owner_already_borrowed = 1
//use(x);
// Uncomment for owner_already_moved = 1
//use_mut(std::move(x));
// Uncomment for another owner_already_borrowed++
//Borrower<int> y = x;
//Uncomment for owner_use_after_move = 1;
//return *x;
}
I have a few ideas I’d like to prototype for live performance using MIDI loopers rather than audio loopers. I have sketched early ideas but I’d like to experiment with the project in earnest. I’m tinkering with tools before mocking up some early designs.
// Call the passed function object N times. This 'unrolls' the loop
// explicitly in assembly code, rather than creating a runtime loop.
template <unsigned int N, typename Fn>
void unroll(Fn&& fn) {
if constexpr (N != 0) {
unroll<N - 1>(fn);
fn(N - 1);
}
}
// extern function ensures the loop is not optimised away
extern void somethin(unsigned int i);
// Call somethin 4 times, passing the count each time
void four_somethins() {
unroll<4>([](unsigned int i) {
somethin(i);
});
}
Now to the meat of the problem, how the tasks actually run. Some of these tasks are going to run in parallel and that could cause threading issues. Looking at the original challenge there is an obvious sticking point. The two tasks ‘Preheat heater’ and ‘Mix reagent’ need to notify ‘Heat Sample’ they are done in a thread safe way so I will need a mutex. Alternatively I could use a thread safe boost::signal to inform the node that a task has finished, but that’s a bit heavyweight.
These are some embarrassingly loose sketches made en route to a friend’s leaving do. I wanted to cement my ideas about the builder class and these led into the idea of how one defines a hardware device. I was getting painfully close to template magic with these ideas but wanted to get an idea for the most expressive DSL for a recipe.
A few days ago Nanopore sent me a technical challenge as part of their interview process. I’ve set up a a GitHub repo to track development progress. These are some notes before I go headlong into coding:
Day 1 – tech challenge received
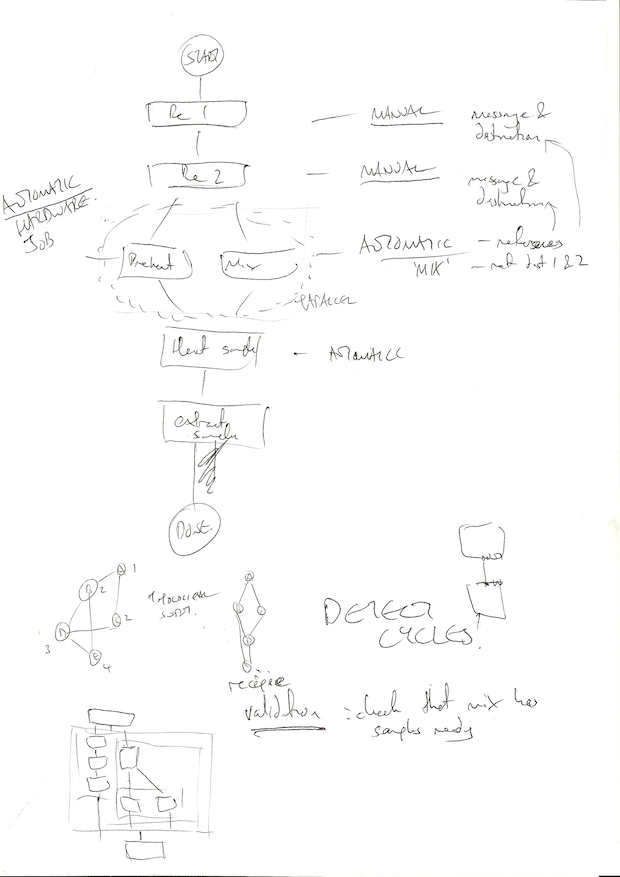
The challenge involves building a DAG for a workflow. The first thing I did on receiving it was sketch out their example DAG to get a better feel for the behaviour of each node:
Forgive the quality of these scans, I’m cobbling this together fast! The first sketch highlighted the scope of the design for the DAG:
Input where user adds sample. I’ll call these input_a, input_b etc.
Output where user removes sample. I’ll call these output_a, output_b etc.
General input/output ‘cells’ which is where the device is moving samples around, which I’m assuming to be a 2×2 grid from seeing the VolTRAX videos. I’ll call these cell_1_1, cell_2_4 etc.
Certain cells do work, e.g. heating, applying magnetic field. I’ll treat these like regular cells but give them special IDs like heater_1.
Example tasks and data required:
Add ingredient (manual): show message; input port ID; destination cell to move sample to.
Mix ingredients (auto): two registers to mix; cell where the sample ends up.
Preheat (auto): heater temperature; heater ID if there is more than one.
Heat sample (auto): input cell location; time on heater; header ID if there is more than one; output cell location.
Extract sample (manual): show message; output port ID.
This highlights some missing data in the DAG, that the operations of moving between certain cells should perhaps be nodes in themselves. For example the ‘heat sample’ task would be simpler if it was split up using move tasks:
Move sample from cell_1_2 to heater_1.
Stay on (preheated) heater_1 for 2 seconds.
Move sample from heater_1 to cell_2_3.
A few other things came up in this sketch:
Being a DAG it needs to avoid cycles.
The ports/cells give me a conceptual device to work with.
Validation. If I know all the inputs and outputs then I can run a validation step to ensure that anything that uses a particular cell or input has had that cell or input set up; i.e. check hardware dependencies.
To run the program the nodes will need to be sorted topologically. Not necessary if nodes are inserted in-order.
My sketch at the bottom left is my thinking about organising parallel data tasks which let to builder concepts detailed in next post. I think I can get a nice DSL together.
Recently I’ve been chipping away at Jamis Buck’s ‘Mazes for Programmers’. I’m loving it and highly recommend the book. The code examples are quick to write, intuitive and good to learn from. They are written in Ruby and quietly introduce good design practices.
Whilst I’m working through the book I’m uploading my work in progress to https://github.com/alexallmont/JamisMazes. It’s been a while since I’ve pushed anything to GitHub because I started working on some of the ‘try at home’ sections at the end of each chapter; as I was working through it I started restructuring the core libraries on a new branch. I’ve gone down the refactor rabbit hole.
Moving to C++
I’ve managed to distract myself further by making my own maze library in C++. At the time of writing the repo https://github.com/alexallmont/MazeCpp is a simple C++ library which links into a demo and unit tests. My goal here was to brush up on my C++14 and experiment with continuous build systems. Over the last few days though I’ve been irked by the clunky design on the first draft. There’s lots of aliasing early on, the code was already feeling flabby.
Playing with templates
Today I’ve been experimenting with a templatised version that compiles down to practically nothing. I wanted to exploit that these mazes are fixed size, so I can use std::array to store data rather than std::vector. This means a huge amount of work can be done at compile time. Today’s experiments are at https://godbolt.org/g/ko0WIz.
The main class Grid2D is declared as a template with fixed rows and columns. Having the rows and column sizes declared at compile time means that a lot of the API boils down to constexpr functions. Rather than have a separate ‘Cell2D’ class, each Grid2D declares a nested Cell class that is a lightweight wrapper for querying individual cells in the maze graph.
I was hoping that I could reduce each cell to be a single integer, it’s index in the grid (row * NUM_ROWS + column). Unfortunately reducing to an int was not possible because each cell has query methods that reference non-static methods in Grid2D, so they also need to store an instance pointer to their owning grid. The alternative to this aliasing would be to pass the grid to every Cell function call, but that breaks the encapsulation and does not read well in code. However when building optimised the pointers boil away.
I’d prefer to store each cells Grid2D by reference rather than pointer and I’m exploring options as to whether that’s possible with std::array. As far as I know one can only use std::array on simple data types, no fancy construction is allowed, so the Cell class is friendly with Grid2D which does all the initialisation.
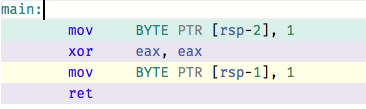
Regardless the simple test case compiles down ridiculously small, just 4 ops!
I’ve been learning more C++ 11/14 and I initially wanted to build a nice API using variadic templates. When used correctly one can build a clean API with templates that compile down to very small code. Unfortunately AVRGCC does not yet support C++ 11/14 so I can’t follow that route. Here’s my bullet point summary of the day’s findings:
Early template classes experiments messy/confusing.
C++0x14 does not work on AVR right now anyway.
Linked lists simply don’t optimise away.
Virtual methods don’t optimise away.
Best approach seems to be general class.
Static functions in a namespace compile even smaller than class.
My strategy here was to start with a nice OOP design and rapidly iterate ideas using Compiler Explorer to see where it took me. I built with AVR gcc 4.5.3 with the flags -Winvalid-pch -Wall -Wno-long-long -pedantic -Os -ggdb -gstabs -mmcu=atmega328p -fdata-sections -ffunction-sections -fsigned-char
Test 1 : Linked lists
My starting point was a singly linked list of AdcInputs. The AdcManager polling the next via interrupt whilst traversing the list. The derived classes would present a nice API.
Given my code sample I was hoping the compiler would be clever enough to optimise a lot away, but I am storing data in virtual classes so there’s a lot of vtable setup, calls and the pointers in the linked list are still used in code:
Tests 2 – (n-1) : No man’s land
Here’s where it gets a bit messy going through my notes because I didn’t keep copies of all of my in-progress code. In summary I realised that virtual classes and linked lists were not the way to go and experimented with template magic and functors before settling on a simple solution of a central do-it-all manager class.
The problem was making a reasonably friendly access interface out of it. For my applications there are only a few variations on the types of ADC interface, they mostly store a uint8_t as the value – with the edge case of using 10 bit resolution – so would it be possible to cram all the other data into another byte? I could use say 2 bits to store the type of interface and the remaining 6 could be used by each interface’s implementation. For example, storing a ‘pushed’ state for a SoftPot. In total that gives me a standard 2 byte struct for each interface which I can simply store in an array for the manager.
The bit wrangling ideas came strongly from this hybrid data structures video. They use a heavily templatized method to access bits whilst remaining robust enough to avoid memory stamping. I’d like to that more in future but for now I’m just using plain old bit fields.
Swapping out the linked lists for a fixed array adds memory overhead because that chunk of memory is always used. However I select AVR chips based on spec; if I only need 3 inputs then I look for the closest match chip rather than an overspecced AtMega328.
This code is an experiment during this stage. It’s not pretty but I’m sharing it because it helped me realise the value of using static correctly in optimisation. Here’s what happens when you remove the static keyword from AdcRunner::update():
Test 3 : template accessors
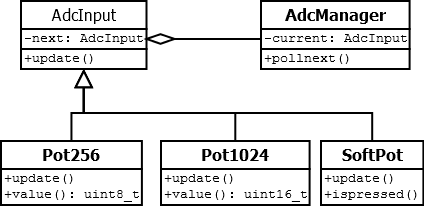
With the manager ‘class’ now simply being a bunch of static functions, I’m using a templatized base class to give the user access to each one. Here’s the core class. ADC_TYPE is an enum that defines my fixed set of ADC interfaces. The interface stores a reference to data which is handled by the manager. The idea is as a client you use these objects on the stack merely as accessors to the manager’s data, and that the manager uses these objects to update its data correctly.
Here’s an example concrete implementation softpot input. It has accessors for getting the value and determining if it is pressed. The update method will be called from the manager, it’s a bit ugly but it’s in progress.
class Softpot : public AdcInput<kSoftPot>
{
public:
Softpot(Data& data) : AdcInput(data) { }
uint8_t getValue() { return m_data.value; }
bool isPressed() { return (m_data.info & (1 << 4)) != 0; }
void adcUpdate(); // TBC... this is how the manager updates this data
};
Here’s some code to get a feel for the API
init_adc();
add_adc<Pot>(0);
add_adc<Softpot>(1);
Pot p1 = get_adc<Pot>(0);
Softpot p2 = get_adc<Softpot>(1);
for (;;)
{
uint8_t val = 0;
if (p2.isPressed())
val = p1.getValue() + p2.getValue();
else
val = p1.getValue() - p2.getValue();
}
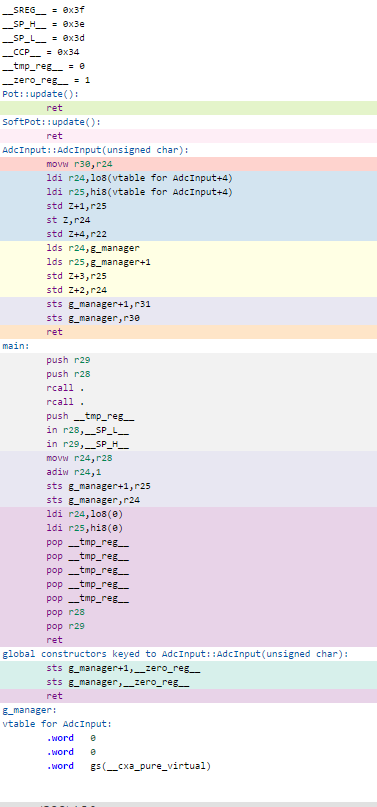
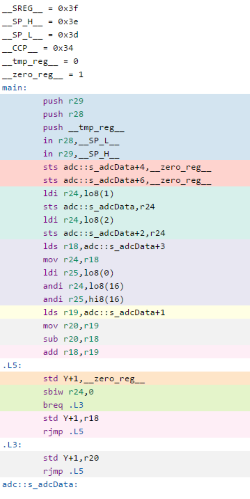
The full version of the test code and compiled output is here and the generated output is on the right.
The current problem with this is that there is no fail-safe on getting the wrong type of object. For example in the above code I have a pot on 0 and a softpot on 1, but there is nothing stopping me trying to read 0 as a softpot. This is not the right place to use exception handling. One option is to store a block of clearly invalid data like 0xFFFF, which you can pick up in debug, but it irks me.
Next step is to try this in action on the AVR and look at the generated assembler with the interrupt handler in place. I have no doubt it will be a little bit longer than writing the code in plain C but I wanted to experiment with something more scalable, and I’ve learned a few things on the way hence this blog post.
Also learned today
Today I needed a nice UML editor so I turned to Stack Overflow for advice. I initially tried Umler, then ArgoUML because I like the developers but it’s a real fiddle (no cut/paste/undo!) so I went Dia which immediately felt nice. Also jogged my UML memory with this guide.
It’s hard to keep blog posts short. Bear with me on this, I’m learning the ropes!
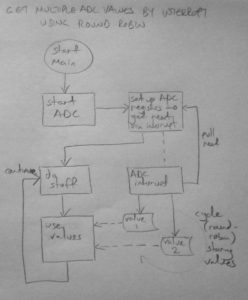
Several of my recent 8 bit microcontroller projects need multiple analogue inputs. I want a nice API that allows me to have different interfaces for getting analogue values, for example reading a straightforward pot as 0-255 or 0-1023, or a SoftPot membrane potentiometer where I may also want to track whether or not it’s
currently pressed.
Reading analogue inputs on AVR chips takes time and the lazy approach to reading an analogue value is to set up the registers to read a value and simply wait for it to come in. You do something like this:
That while loop is just eating cycles whilst we’re waiting for the ADC to return a result.
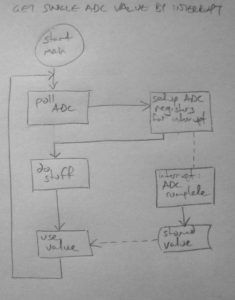
The best way to avoid this wait is to set up the ADC to start reading a value and when it’s ready send an interrupt to get the result.
The interrupt can either use the value immediately or stash it away in a stored value so it can be picked up later on in the main loop.
This approach saves wasting cycles but still has a problem: the ADC can only read one value at a time and I need multiple inputs.
The workaround for this is to make the interrupt run continually and constantly read each ADC value in turn.
The poll requests requests a value for a certain analogue input and when the ADC interrupt is fired off, it re-polls for the next one. This runs perpetually whilst interrupts are enabled.
The interrupt can act on the values immediately or – if we’re not concerned about keeping everything perfectly in sync – the values can simply be stored in data so it can be picked up in the main thread.
In the next post I’ll explain how I iterated this round-robin in building a fast and clean API for AVR chips.
Disclaimer to protect my CV: this is not something I do professionally!
I often need to generate pitch or sample lookup tables for my AVR projects. I usually generate these C++ headers with little ruby scripts. An evil thought struck me during a long drive… I don’t like these separate little scripts, I want the script inside the header, so if you #include it you get the data, but if you run it with ruby it rebuilds itself.
The thought preoccupied me for the journey. Preprocessor macros start with a hash, and ruby uses hashes as comments, so you can hide ruby code in a #if 0 block.
The problem was then how to stop ruby from parsing the C++ the file contains. That’s simple enough, you can hide =begin and =end in #if blocks.
The file reading and writing itself is handled using gsub() and some careful regexing. It searches for the tailing end of the table declaration and the hash of the #if that trails it, and the replaces that block with generated values.
Just to be a swine I’ve condensed the Ruby to be borderline unreadable. Save this as ‘notes.h’ and run it through ruby:
#if 0# Run 'ruby notes.h' and this rebuilds itself.
i=IO.read($0);IO.write($0,i.gsub(/(\]\s=\s{).+?#/m,"\\1 \n #{1024.times.collect{|n|(((44100.0*64.0)/(2.0**(n.to_f/(12*16))*110.0))).to_i}.join(",\n ")}\n};\n#"))=begin
#endifuint16_t freq[1024]={25658,25565,// ... the rest here will be regenerated641,638};#if 0=end
#endif
#if 0
# Run 'ruby notes.h' and this rebuilds itself.
i=IO.read($0);IO.write($0,i.gsub(/(\]\s=\s{).+?#/m,"\\1 \n #{1024.times.collect{|n|(((44100.0*64.0)/(2.0**(n.to_f/(12*16))*110.0))).to_i}.join(",\n ")}\n};\n#"))
=begin
#endif
uint16_t freq[1024] = {
25658,
25565,
// ... the rest here will be regenerated
641,
638
};
#if 0
=end
#endif
Note the regex can’t just search for the ‘] = {‘ verbatim because it would pick up the first instance of that expression in the gsub itself; this code is reading its own text and it would replace the regex! I bypass this by swapping spaces for \s ‘]\s=\s‘.
Here the evil ends. #include "notes.h" works fine and you can rebuild any time – and risk trashing everything if you have made the tiniest typo :) Not a good way to approach development but a fun puzzle. The next challenge is to do this with compile-time table generation using variadic templates.



 Several of my recent 8 bit microcontroller projects need multiple analogue inputs. I want a nice API that allows me to have different interfaces for getting analogue values, for example reading a straightforward pot as 0-255 or 0-1023, or a SoftPot membrane potentiometer where I may also want to track whether or not it’s
Several of my recent 8 bit microcontroller projects need multiple analogue inputs. I want a nice API that allows me to have different interfaces for getting analogue values, for example reading a straightforward pot as 0-255 or 0-1023, or a SoftPot membrane potentiometer where I may also want to track whether or not it’s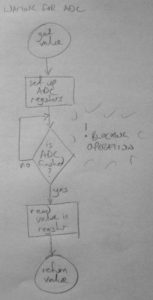
 The best way to avoid this wait is to set up the ADC to start reading a value and when it’s ready send an interrupt to get the result.
The best way to avoid this wait is to set up the ADC to start reading a value and when it’s ready send an interrupt to get the result.