I’ve been learning more C++ 11/14 and I initially wanted to build a nice API using variadic templates. When used correctly one can build a clean API with templates that compile down to very small code. Unfortunately AVRGCC does not yet support C++ 11/14 so I can’t follow that route. Here’s my bullet point summary of the day’s findings:
- Early template classes experiments messy/confusing.
- C++0x14 does not work on AVR right now anyway.
- Linked lists simply don’t optimise away.
- Virtual methods don’t optimise away.
- Best approach seems to be general class.
- Static functions in a namespace compile even smaller than class.
My strategy here was to start with a nice OOP design and rapidly iterate ideas using Compiler Explorer to see where it took me. I built with AVR gcc 4.5.3 with the flags -Winvalid-pch -Wall -Wno-long-long -pedantic -Os -ggdb -gstabs -mmcu=atmega328p -fdata-sections -ffunction-sections -fsigned-char
Test 1 : Linked lists
My starting point was a singly linked list of AdcInputs. The AdcManager polling the next via interrupt whilst traversing the list. The derived classes would present a nice API.
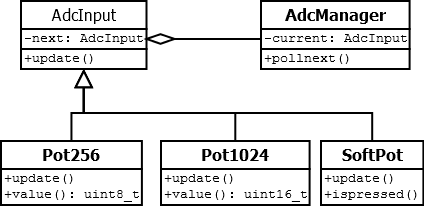
Given my code sample I was hoping the compiler would be clever enough to optimise a lot away, but I am storing data in virtual classes so there’s a lot of vtable setup, calls and the pointers in the linked list are still used in code:
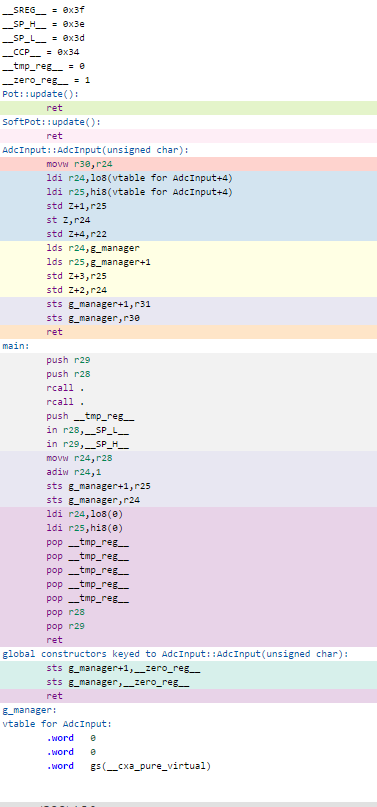
Tests 2 – (n-1) : No man’s land
Here’s where it gets a bit messy going through my notes because I didn’t keep copies of all of my in-progress code. In summary I realised that virtual classes and linked lists were not the way to go and experimented with template magic and functors before settling on a simple solution of a central do-it-all manager class.
The problem was making a reasonably friendly access interface out of it. For my applications there are only a few variations on the types of ADC interface, they mostly store a uint8_t as the value – with the edge case of using 10 bit resolution – so would it be possible to cram all the other data into another byte? I could use say 2 bits to store the type of interface and the remaining 6 could be used by each interface’s implementation. For example, storing a ‘pushed’ state for a SoftPot. In total that gives me a standard 2 byte struct for each interface which I can simply store in an array for the manager.
The bit wrangling ideas came strongly from this hybrid data structures video. They use a heavily templatized method to access bits whilst remaining robust enough to avoid memory stamping. I’d like to that more in future but for now I’m just using plain old bit fields.
Swapping out the linked lists for a fixed array adds memory overhead because that chunk of memory is always used. However I select AVR chips based on spec; if I only need 3 inputs then I look for the closest match chip rather than an overspecced AtMega328.
This code is an experiment during this stage. It’s not pretty but I’m sharing it because it helped me realise the value of using static correctly in optimisation. Here’s what happens when you remove the static keyword from AdcRunner::update():

Test 3 : template accessors
With the manager ‘class’ now simply being a bunch of static functions, I’m using a templatized base class to give the user access to each one. Here’s the core class. ADC_TYPE is an enum that defines my fixed set of ADC interfaces. The interface stores a reference to data which is handled by the manager. The idea is as a client you use these objects on the stack merely as accessors to the manager’s data, and that the manager uses these objects to update its data correctly.
template <Type ADC_TYPE>
class AdcInput
{
public:
AdcInput(Data& data) : m_data(data) { }
static Type getType() { return ADC_TYPE; }
static uint8_t getTypeBits() { return (uint8_t)getType() & 0x03; }
protected:
Data& m_data;
};
Here’s an example concrete implementation softpot input. It has accessors for getting the value and determining if it is pressed. The update method will be called from the manager, it’s a bit ugly but it’s in progress.
class Softpot : public AdcInput<kSoftPot>
{
public:
Softpot(Data& data) : AdcInput(data) { }
uint8_t getValue() { return m_data.value; }
bool isPressed() { return (m_data.info & (1 << 4)) != 0; }
void adcUpdate(); // TBC... this is how the manager updates this data
};
Here’s some code to get a feel for the API
init_adc();
add_adc<Pot>(0);
add_adc<Softpot>(1);
Pot p1 = get_adc<Pot>(0);
Softpot p2 = get_adc<Softpot>(1);
for (;;)
{
uint8_t val = 0;
if (p2.isPressed())
val = p1.getValue() + p2.getValue();
else
val = p1.getValue() - p2.getValue();
}
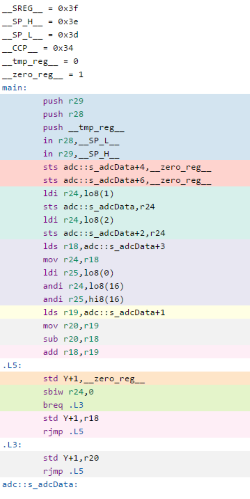
The full version of the test code and compiled output is here and the generated output is on the right.
The current problem with this is that there is no fail-safe on getting the wrong type of object. For example in the above code I have a pot on 0 and a softpot on 1, but there is nothing stopping me trying to read 0 as a softpot. This is not the right place to use exception handling. One option is to store a block of clearly invalid data like 0xFFFF, which you can pick up in debug, but it irks me.
Next step is to try this in action on the AVR and look at the generated assembler with the interrupt handler in place. I have no doubt it will be a little bit longer than writing the code in plain C but I wanted to experiment with something more scalable, and I’ve learned a few things on the way hence this blog post.
Also learned today
- Today I needed a nice UML editor so I turned to Stack Overflow for advice. I initially tried Umler, then ArgoUML because I like the developers but it’s a real fiddle (no cut/paste/undo!) so I went Dia which immediately felt nice. Also jogged my UML memory with this guide.
- It’s hard to keep blog posts short. Bear with me on this, I’m learning the ropes!